
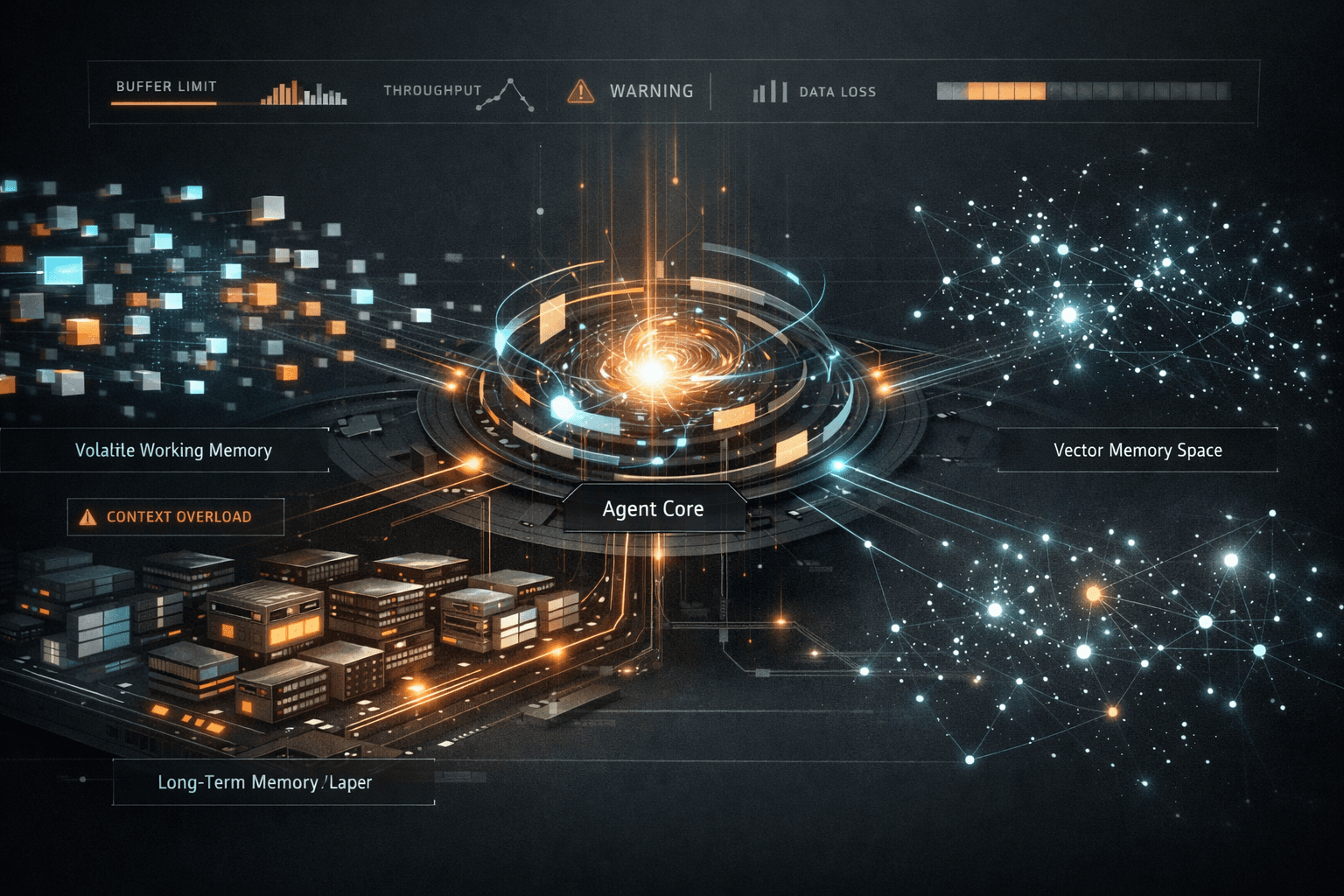
Memory in AI Agents: Short-Term, Long-Term, and Vector Memory Explained
Most teams I meet swear their agent problems are model problems. Too small. Too dumb. Wrong temperature. But when you sit with the logs long enough, a quieter pattern shows up. The agent didn’t fail because it couldn’t reason. It failed because it forgot. Or worse, remembered the wrong thing at the wrong time. Over the years, across support bots, research agents, and internal automation, I’ve learned that memory assumptions—not model choice—are where agentic systems quietly bleed money.
That’s what we need to talk about.
Memory is the real architecture, not the model
When people say “AI agent,” they usually picture a loop that calls an LLM, maybe with tool-calling bolted on. That mental model is already outdated. In production, the agent’s behavior is shaped far more by how memory is stored, retrieved, decayed, and scoped than by which model sits behind the prompt.
Context window limits force every serious agent to externalize memory. The moment you do that, you’re no longer building a chatbot. You’re designing an agent memory architecture. Ignore that reality and you get agents that feel smart in demos and brittle in week three.
Short-term memory, long-term memory, and vector memory aren’t features. They’re trade-offs. Each solves a different failure mode, and each introduces new ones if you apply it lazily.
How short-term memory works in AI agents
Short-term memory is the agent’s working memory. It’s what lives inside the context window or just outside it in a rolling buffer. Conversation history, recent tool outputs, intermediate reasoning state, and current goals all compete for space here.
Most teams treat short-term memory as a transcript. That’s a mistake. Agents don’t need verbatim recall; they need state. The difference matters. A raw conversation log grows until it chokes the context window. A structured working memory stays small because it’s opinionated about what matters.
In real systems, short-term memory should behave like a scratchpad with eviction rules. Recent user intent stays. Tool results stay until consumed. Dead ends disappear quickly. If everything stays, nothing is salient.
This is where agent state management quietly decides success or failure. An agent that can’t forget will hallucinate continuity. It will reference tools it no longer has access to, reuse stale assumptions, and confidently walk into contradictions you thought you’d “prompted away.”
Short-term memory should decay aggressively. If that makes you uncomfortable, that’s usually a sign you’re relying on it to do long-term work it was never meant to do.
The illusion of “just increase the context window”
Every few months, someone suggests solving memory by throwing a bigger context window at the problem. It works briefly, then collapses under its own weight. Larger windows amplify noise. They don’t create understanding.
I’ve seen agents with massive context windows perform worse than tightly scoped ones because retrieval becomes implicit and uncontrolled. The model decides what matters, not your system. That’s not architecture; that’s hope.
Short-term memory is about immediacy, not history. Treat it like RAM, not a hard drive.
Designing long-term memory for agentic systems
Long-term memory is where agent builders get ambitious and reckless at the same time. This is where you store past interactions, learned preferences, episodic events, and durable facts the agent should carry forward.
The first trap is assuming long-term memory should be comprehensive. It shouldn’t. Long-term memory should be selective, curated, and opinionated. If everything is remembered, retrieval becomes meaningless.
I split long-term memory into episodic memory and semantic memory. Episodic memory captures things that happened: a user complained, a task failed, a decision was overridden. Semantic memory captures abstractions: this user prefers email summaries, this API rate-limits aggressively, this workflow breaks on Fridays.
Most systems jumble the two. That’s why agents recall irrelevant anecdotes instead of the rule that actually matters.
Long-term memory also needs write discipline. Tool-calling agents should not be allowed to write memories freely. Every memory write is a schema decision. If you don’t control it, your agent will store junk with high confidence.
This is where experience changes your posture. Early on, you want agents to remember everything. After your first memory-related incident in production, you want them to remember almost nothing unless explicitly promoted.
There’s a deeper architectural realization here that connects directly to designing and scaling agentic systems in production . Memory isn’t storage. It’s policy.
Memory decay is not optional
Human memory decays for a reason. Agent memory needs the same mercy.
Without decay, long-term memory becomes a liability. Old assumptions persist after the world changes. Users evolve. APIs change behavior. Policies shift. An agent that never forgets will confidently act on outdated truths.
Decay can be time-based, usage-based, or confidence-based. I prefer usage-based decay tied to successful retrieval. Memories that help get reinforced. Memories that never get used fade away. This keeps semantic memory aligned with reality, not history.
If you’re not designing decay, you’re designing future bugs.
Vector memory vs database memory for AI agents
This is where debates get noisy and unproductive. Vector memory is not a replacement for databases. It’s a retrieval mechanism with a very specific strength: semantic similarity.
Vector embeddings shine when the agent needs to recall “things like this.” Prior tickets with similar language. Past decisions with comparable constraints. Documentation that matches intent, not keywords. That’s why vector memory pairs naturally with retrieval-augmented generation.
But vector memory is terrible at precision. It doesn’t respect exactness, ordering, or transactional truth. If you need authoritative facts, structured state, or auditability, you want database memory.
The mistake is choosing one. Mature agent memory architectures use both. Vector memory for fuzzy recall. Database memory for canonical state.
The real design question isn’t which to use. It’s when to consult which, and under what confidence thresholds. An agent that defaults to vector recall for factual decisions will eventually invent its own reality. An agent that avoids vector memory entirely will feel rigid and forgetful.
This balance shows up clearly when you study common AI agent architecture patterns in real systems. The winning systems don’t argue about tools. They orchestrate them.
Retrieval is behavior, not plumbing
Most teams treat memory retrieval as an infrastructure concern. It isn’t. Retrieval shapes agent behavior as much as reasoning does.
What you retrieve first biases the entire chain of thought. Retrieve too much and the agent drowns. Retrieve too little and it hallucinates gaps. Retrieve the wrong type of memory and it solves the wrong problem perfectly.
This is where memory indexing matters. Separate indexes for episodic and semantic memory. Separate thresholds for vector similarity depending on task criticality. Different retrieval strategies for planning versus execution.
Planning agents should retrieve broadly, looking for patterns. Execution agents should retrieve narrowly, looking for constraints. Mixing those modes is how agents overthink simple tasks and underthink dangerous ones.
If this sounds abstract, it isn’t. It’s the difference between an agent that pauses before making an irreversible API call and one that cheerfully burns your quota because it “felt similar” to a previous task.
A necessary digression on RAG hype
Retrieval-augmented generation is often sold as a silver bullet for memory. It isn’t. RAG is a technique, not a strategy.
I’ve seen RAG pipelines wired into agents that had no concept of memory scope, decay, or authority. The agent retrieved documents, summarized them confidently, and still made the wrong call because the retrieval was context-blind.
RAG works when retrieval is intentional and memory-aware. It fails when it’s bolted on as a patch for context window limits.
The uncomfortable truth is that RAG forces you to confront memory design. If you don’t, it just makes failure modes harder to debug.
That digression matters because once you return to the core problem, the pattern is clear. Memory is not additive. Every new memory source increases complexity nonlinearly.
Tool-calling agents expose memory flaws fast
Tool-calling agents are unforgiving. They act in the real world. They make memory mistakes expensive.
An agent that forgets it already retried a failed API call will loop until something breaks. An agent that remembers a deprecated endpoint will keep calling it long after you’ve patched the code. An agent that confuses episodic memory with semantic truth will escalate the wrong issue to the wrong team.
This is why I’m opinionated about gating memory writes and scoping memory reads. Tools should influence memory only after success, not after intent. Failed actions should inform episodic memory, not rewrite semantic assumptions.
When teams complain that tool-calling agents are “unpredictable,” it’s usually a memory design problem wearing a different mask.
Context windows are a constraint, not a crutch
Context window limits force discipline. They’re not an obstacle to be bypassed; they’re a reminder that attention is finite.
The best agents I’ve worked on treat the context window as sacred. Only the highest-signal information earns a place. Everything else lives outside, waiting to be retrieved deliberately.
This mindset changes how you write prompts, how you summarize memory, and how you design agent loops. It also changes how you debug. You stop asking “why did the model do this?” and start asking “why did we show it that?”
That shift alone separates experimental agents from production systems.
Opinionated conclusions from hard-earned scars
If you take nothing else from this, take this: memory architecture is where agentic systems either mature or rot.
Short-term memory should be small, structured, and ruthless about forgetting. Long-term memory should be selective, decaying, and carefully written. Vector memory should be treated as a probabilistic assistant, not a source of truth. Database memory should anchor reality.
Most importantly, memory decisions should be explicit. If you can’t explain why a piece of information was remembered, retrieved, or forgotten, your agent is already lying to you. It just hasn’t cost you yet.
I’ve watched teams rewrite entire agent stacks when a few principled memory decisions would have stabilized everything. Models will keep getting better. Context windows will keep growing. None of that will save an agent that remembers badly.
Sometimes progress comes faster with another brain in the room. If that helps, let’s talk — free consultation at Agents Arcade .
Majid Sheikh is the CTO and Agentic AI Developer at Agents Arcade, specializing in agentic AI, RAG, FastAPI, and cloud-native DevOps systems.